

Meta is adding another Llama to its herd—and this one knows how to code. On Thursday, Meta unveiled “Code Llama,” a new large language model (LLM) based on Llama 2 that is designed to assist programmers by generating and debugging code. It aims to make software development more efficient and accessible, and it’s free for commercial and research use.
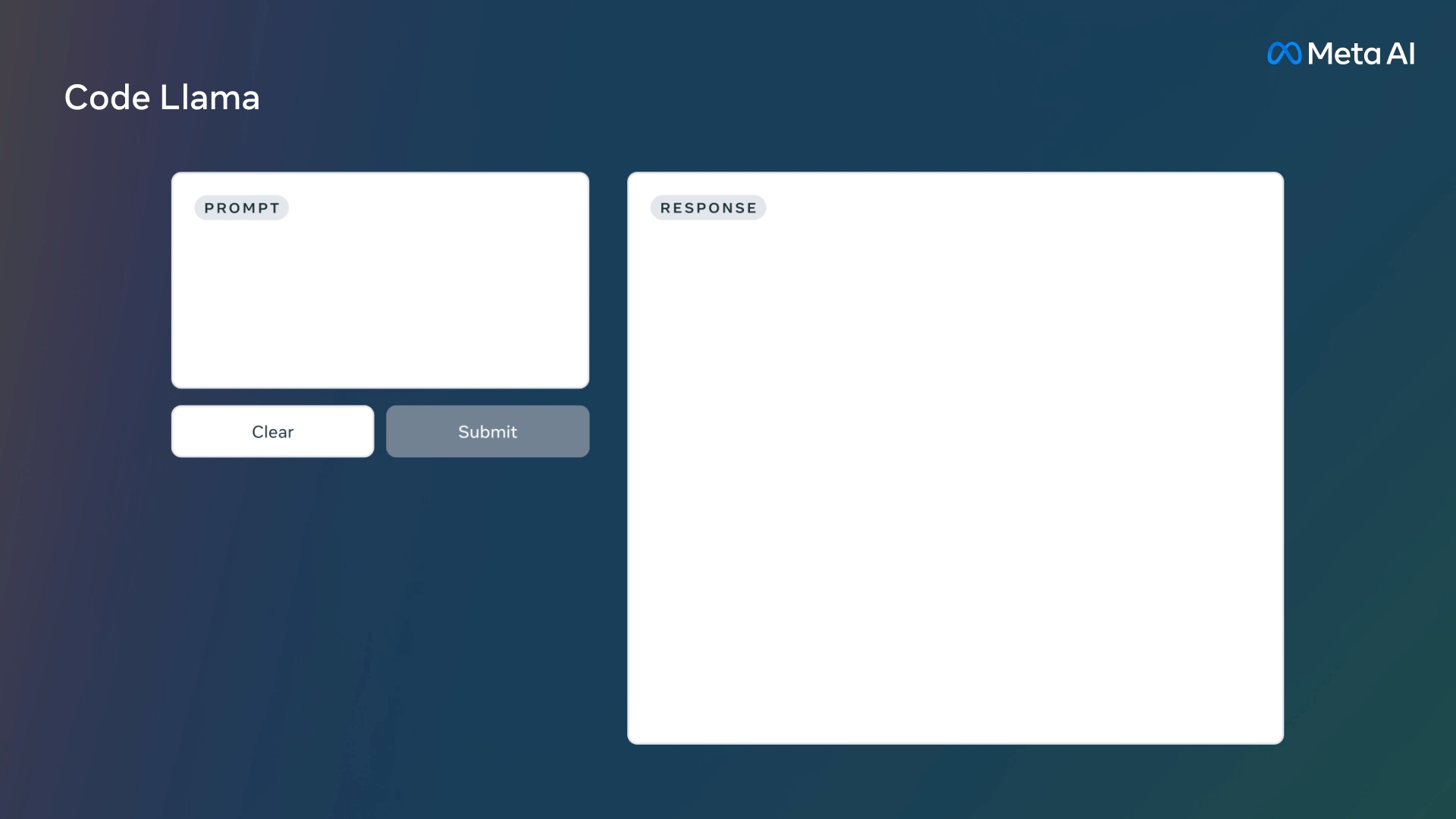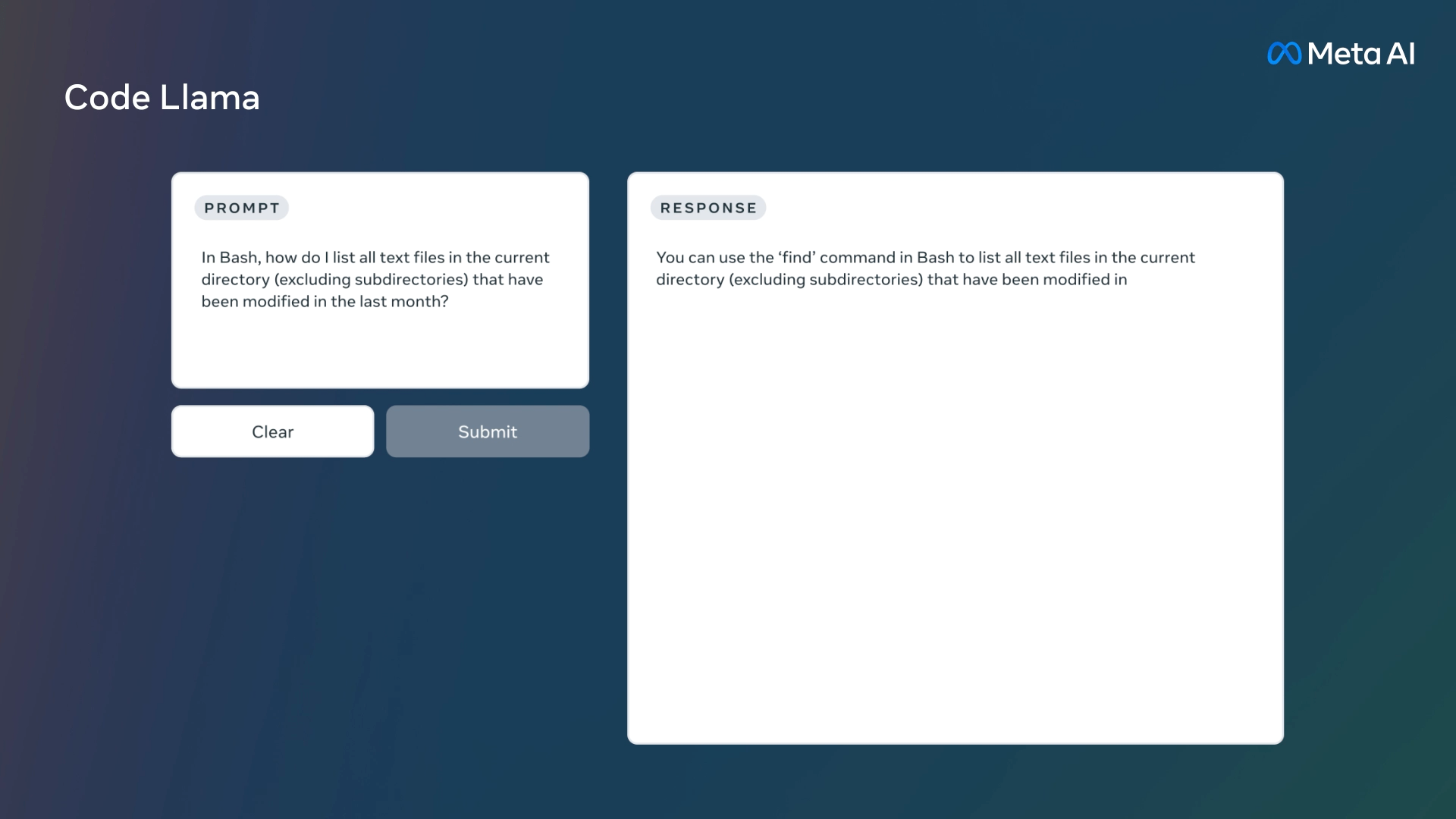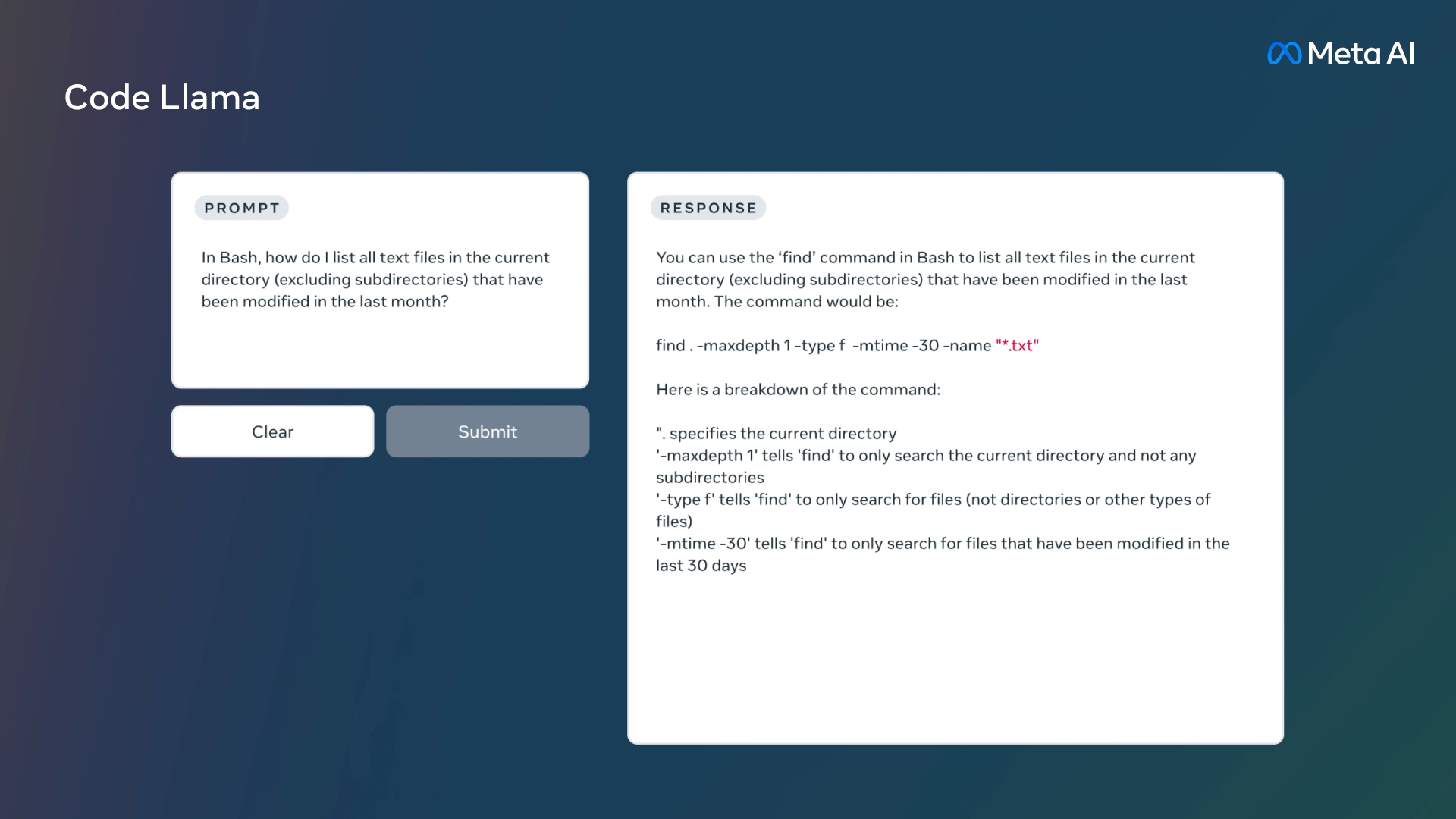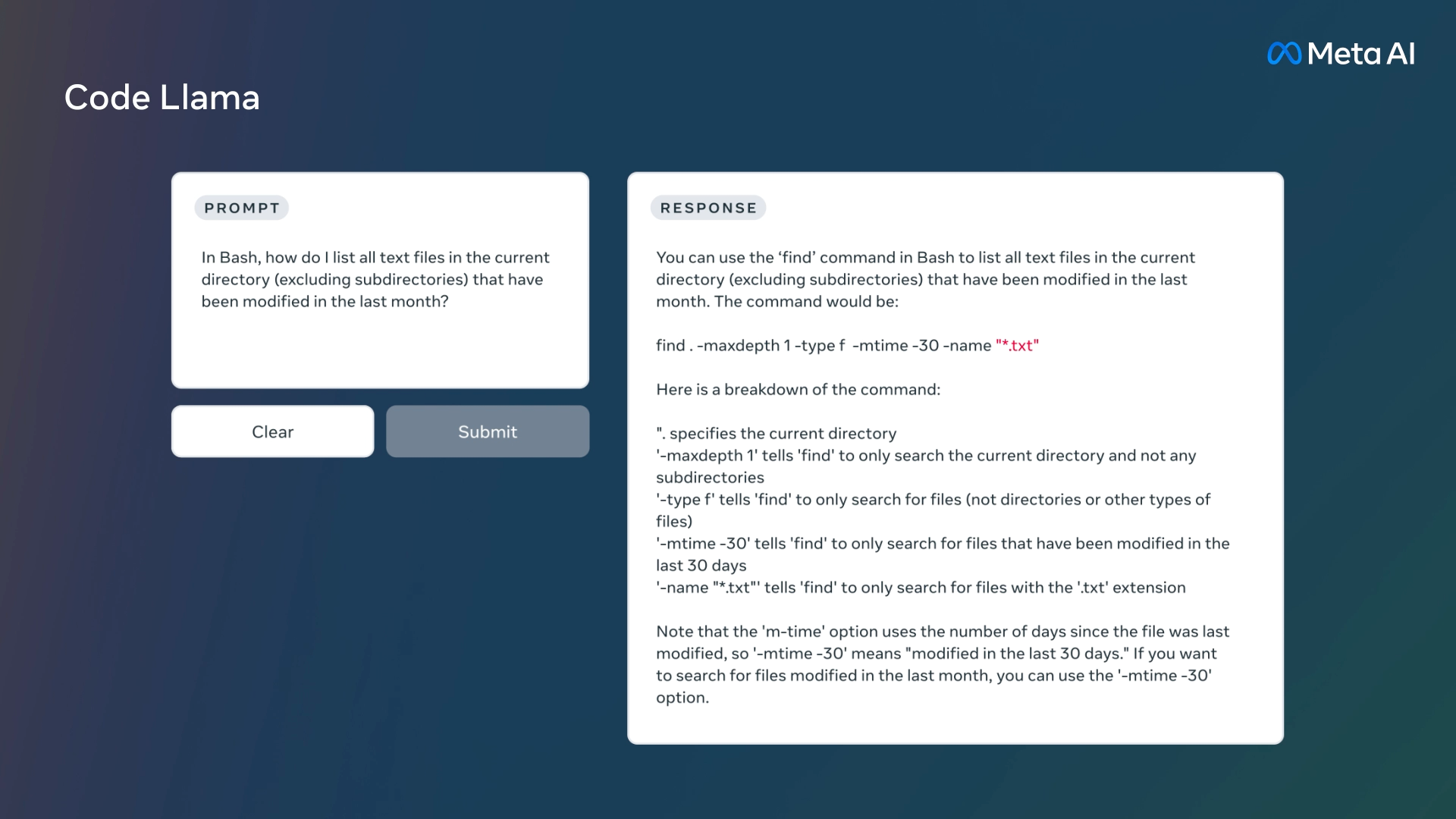
Much like ChatGPT and GitHub Copilot Chat, you can ask Code Llama to write code using high-level instructions, such as “Write me a function that outputs the Fibonacci sequence.” Or it can assist with debugging if you provide a sample of problematic code and ask for corrections.
As an extension of Llama 2 (released in July), Code Llama builds off of weights-available LLMs Meta has been developing since February. Code Llama has been specifically trained on source code data sets and can operate on various programming languages, including Python, Java, C++, PHP, TypeScript, C#, Bash scripting, and more.
Notably, Code Llama can handle up to 100,000 tokens (word fragments) of context, which means it can evaluate long programs. To compare, ChatGPT typically only works with around 4,000-8,000 tokens, though longer context models are available through OpenAI’s API. As Meta explains in its more technical write-up:
Aside from being a prerequisite for generating longer programs, having longer input sequences unlocks exciting new use cases for a code LLM. For example, users can provide the model with more context from their codebase to make the generations more relevant. It also helps in debugging scenarios in larger codebases, where staying on top of all code related to a concrete issue can be challenging for developers. When developers are faced with debugging a large chunk of code they can pass the entire length of the code into the model.
Meta’s Code Llama comes in three sizes: 7, 13, and 34 billion parameter versions. Parameters are numerical elements of the neural network that get adjusted during the training process (before release). More parameters generally mean greater complexity and higher capability for nuanced tasks, but they also require more computational power to operate.
The different parameter sizes offer trade-offs between speed and performance. While the 34B model is expected to provide more accurate coding assistance, it is slower and requires more memory and GPU power to run. In contrast, the 7B and 13B models are faster and more suitable for tasks requiring low latency, like real-time code completion, and can run on a single consumer-level GPU.
Meta has also released two specialized variations: Code Llama – Python and Code Llama – Instruct. The Python variant is optimized specifically for Python programming (“fine-tuned on 100B tokens of Python code”), which is an important language in the AI community. Code Llama – Instruct, on the other hand, is tailored to better interpret user intent when provided with natural language prompts.
Additionally, Meta says the 7B and 13B base and instruct models have also been trained with “fill-in-the-middle” (FIM) capability, which allows them to insert code into existing code, which helps with code completion.
License and data set
Code Llama is available with the same license as Llama 2, which provides weights (the trained neural network files required to run the model on your machine) and allows research and commercial use, but with some restrictions laid out in an acceptable use policy.
Meta has repeatedly stated its preference for an open approach to AI, although its approach has received criticism for not being fully “open source” in compliance with the Open Source Initiative. Still, what Meta provides and allows with its license is far more open than OpenAI, which does not make the weights or code for its state-of-the-art language models available.
Meta has not revealed the exact source of its training data for Code Llama (saying it’s based largely on a “near-deduplicated dataset of publicly available code”), but some suspect that content scraped from the StackOverflow website may be one source. On X, Hugging Face data scientist Leandro von Werra shared a potentially hallucinated discussion about a programming function that included two real StackOverflow user names.
In the Code Llama research paper, Meta says, “We also source 8% of our samples data from natural language datasets related to code. This dataset contains many discussions about code and code snippets included in natural language questions or answers.”
Still, von Werra would like to see specifics cited in the future. “It would be great for reproducibility and sharing knowledge with the research community to disclose what data sources were used during training,” von Werra wrote. “Even more importantly it would be great to acknowledge that these communities contributed to the success of the resulting models.”