

On Thursday, OpenAI announced the launch of GPT-4o mini, a new, smaller version of its latest GPT-4o AI language model that will replace GPT-3.5 Turbo in ChatGPT, reports CNBC and Bloomberg. It will be available today for free users and those with ChatGPT Plus or Team subscriptions and will come to ChatGPT Enterprise next week.
GPT-4o mini will reportedly be multimodal like its big brother (which launched in May), with image inputs currently enabled in the API. OpenAI says that in the future, GPT-4o mini will be able to interpret images, text, and audio, and also will be able to generate images.
GPT-4o mini supports 128K tokens of input context and a knowledge cutoff of October 2023. It’s also very inexpensive as an API product, costing 60 percent less than GPT-3.5 Turbo at 15 cents per million input tokens and 60 cents per million output tokens. Tokens are fragments of data that AI language models use to process information.
Notably, OpenAI says that GPT-4o mini will be the company’s first AI model to use a new technique called “instruction hierarchy” that will make an AI model prioritize some instructions over others, which may make it more difficult for people to use to perform prompt injection attacks or jailbreaks, or system prompt extractions that subvert built-in fine-tuning or directives given by a system prompt.
Once the model is in the public’s hands (GPT-4o mini is currently not available in our instance of ChatGPT), we’ll surely see people putting this new protection method to the test.
Performance
Predictably, OpenAI says that GPT-4o mini performs well on an array of benchmarks like MMLU (undergraduate level knowledge) and HumanEval (coding), but the problem is that those benchmarks don’t actually mean much, and few measure anything useful when it comes to actually using the model in practice. That’s because the feel of quality from the output of a model has more to do with style and structure at times than raw factual or mathematical capability. This kind of subjective “vibemarking” is one of the most frustrating things in the AI space right now.
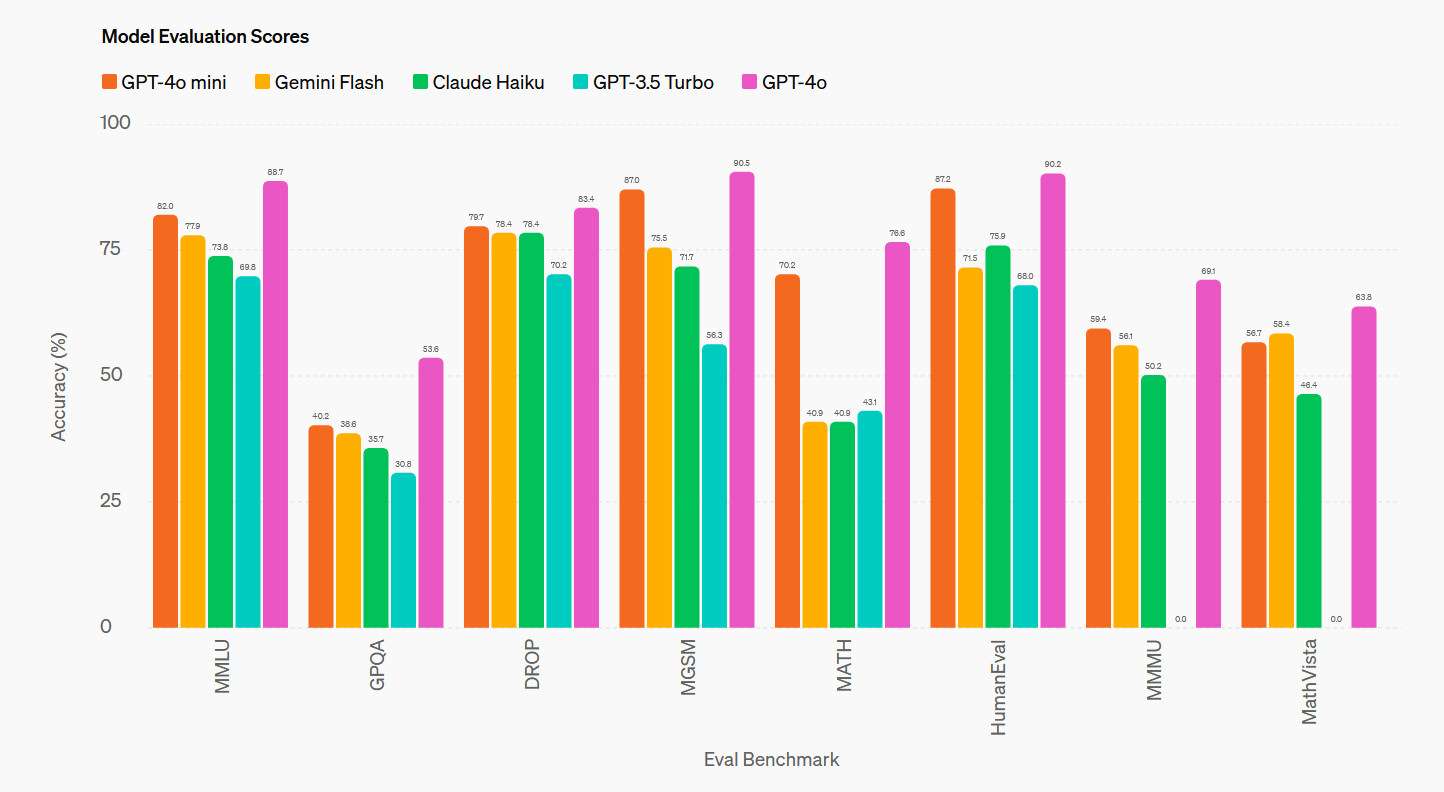
So we’ll tell you this: OpenAI says the new model outperformed last year’s GPT-4 Turbo on the LMSYS Chatbot Arena leaderboard, which measures user ratings after having compared the model to another one at random. But even that metric isn’t as useful as once hoped in the AI community, because people have been noticing that even though mini’s big brother (GPT-4o) regularly outperforms GPT-4 Turbo on Chatbot Arena, it tends to produce dramatically less useful outputs in general (they tend to be long-winded, for example, or perform tasks you didn’t ask it to do).
The value of smaller language models
OpenAI isn’t the first company to release a smaller version of an existing language model. It’s a common practice in the AI industry from vendors such as Meta, Google, and Anthropic. These smaller language models are designed to perform simpler tasks at a lower cost, such as making lists, summarizing, or suggesting words instead of performing deep analysis.
Smaller models are typically aimed at API users, which pay a fixed price per token input and output to use the models in their own applications, but in this case, offering GPT-4o mini for free as part of ChatGPT would ostensibly save money for OpenAI as well.
OpenAI’s head of API product, Olivier Godement, told Bloomberg, “In our mission to enable the bleeding edge, to build the most powerful, useful applications, we of course want to continue doing the frontier models, pushing the envelope here. But we also want to have the best small models out there.”
Smaller large language models (LLMs) usually have fewer parameters than larger models. Parameters are numerical stores of value in a neural network that store learned information. Having fewer parameters means an LLM has a smaller neural network, which typically limits the depth of an AI model’s ability to make sense of context. Larger-parameter models are typically “deeper thinkers” by virtue of the larger number of connections between concepts stored in those numerical parameters.
However, to complicate things, there isn’t always a direct correlation between parameter size and capability. The quality of training data, the efficiency of the model architecture, and the training process itself also impact a model’s performance, as we’ve seen in more capable small models like Microsoft Phi-3 recently.
Fewer parameters mean fewer calculations required to run the model, which means either less powerful (and less expensive) GPUs or fewer calculations on existing hardware are necessary, leading to cheaper energy bills and a lower end cost to the user.